
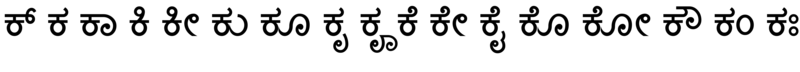
Improving Kannada Fonts - Adding Opentype substitution rules
Dec 3, 2013
2 minutes read.
ಕನ್ನಡ
kannada
fonts
In my previous blog we discussed about the approach to improve Kannada fonts, in this blog we will discuss about adding rules to a font using fontforge python.
Below image shows all the consonant forms of Kannada letter "ka", we will split that into different groups based on type of font rule required. (Read OpenType specification to understand more about rules)
Group one: No rules required
If Unicode code points and Glyph ordering is same then no need to add any rules in font. (Some times positional rules may be required, we will discuss about positional rules later)

Consonant forms identified in this group are

Group two: above base substitution - separate ligature
If the required shape can’t be achieved by joining two or more base glyphs as group 1, then we need separate ligature.

Rule:
sub \uni0C95 \uni0CBF by \uni0C95_uni0CBF.abvs;Where uni0C95 uni0CBF and uni0C95_uni0CBF.abvs are glyph names(Unicode code of "ka" is U+0C95) (Refer).
In #languageSummitPune we(me, Pravin, Sneha, Santhosh and many others) discussed lot about glyph naming standard, will write about importance of glyph names in my next blog.
Group three: above base substitution - Using modified glyph of base glyph
Sometimes we can achieve the required shape by using half shape of base glyph instead of creating separate ligature as in group 2.

Following consonants can be derived using half form of "ka"

Rule:
sub \uni0C95' [\uni0CCD \uni0CBE \uni0CC6 \uni0CCA \uni0CCC] by \uni0C95.half;Group four: No rule required because of Normalization
Some letters in Kannada Unicode normalizes into two or more Unicode characters for which rules will be applied(Refer).
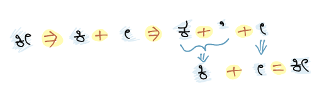
For following consonants no rules required.

Featurefile
We can create featurefile and import all rules into the font using fontforge tool. Read this article to know more about featurefile syntax and specification.
For consonant forms of "ka" final featurefile looks like this..
lookup kn_abvs_lookup1 {
lookupflag 0;
sub \uni0C95 \uni0CBF by \uni0C95_uni0CBF.abvs;
} kn_abvs_lookup1;
lookup kn_abvs_lookup2 {
lookupflag 0;
sub \uni0C95' [\uni0CCD \uni0CBE \uni0CC6 \uni0CCA \uni0CCC] by \uni0C95.half;
} kn_abvs_lookup2;
feature abvs {
script knd2;
language dflt;
lookup kn_abvs_lookup1;
lookup kn_abvs_lookup2;
script knda;
language dflt;
lookup kn_abvs_lookup1;
lookup kn_abvs_lookup2;
} abvs;Once we save the above content in knda_gsub.fea, download the python script from here and run
python apply_gsub_featurefile.py <sfd file path> <fea file path>For example:
python apply_gsub_featurefile.py Lohit-Kannada.sfd knda_gsub.feaAbout Aravinda Vishwanathapura
Co-Founder & CTO at Kadalu Technologies, Creator of Sanka, Creator of Chitra, GlusterFS core team member, Maintainer of Kadalu Storage