

Improving Kannada Fonts - Glyph Names
Dec 24, 2013
4 minutes read.
ಕನ್ನಡ
kannada
fonts
During #languageSummitPune, Pravin explained about glyph naming specification by adobe and its benifits.
Glyph is a entity inside font which holds the co-ordinates information about a shape(letter). For most use cases glyph names doesn’t matter, it is font developers choice to give different names to the glyphs and write font rules according to their glyph names. Rendering engine always deals with Unicode values and font returns respective glyphs to display based on the rules and glyphs inside font.
So what is the problem?
PDF. pdf displays unicode chars even though no rendering support present in the system(thats why it is called portable documents :P), how it is possible? At the time of pdf generation instead of storing unicode values it stores the glyph sequence of the text and embed’s the font. While viewing it arranges the glyphs as per the sequence and displays it, no need to worry about font/rendering rules.
When user types some phrase to find inside pdf, pdf readers will try to convert unicode value of input phrase into glyph sequence and looks inside pdf for that sequence. If each font uses its own glyph names it not possible to reverse lookup by pdf reader and text search fails.
Adobe Glyph specification suggests to name the glyph as unicode value with uni prefix. For example Unicode value of Kannada letter ಅ is U+0C85, so we have to name the glyph ಅ as uni0C85.
Some font developers prefer to name the glyphs as some human readable name instead of code name(like avowelknd, kaknd etc). Human readable names may help at the time of adding rules, but their are other problems associated with it. If we use our own naming in the font then we should take care adding those names in glyphlist.txt. We will endup introducing one more naming standard for each language, also untill all pdf reader software picks up the updated glyphlist, new names will not be used in pdf search. Another important problem is that all fonts developer will not agree to use the glyph naming proposed by one font developer. (For example one can propose language name as prefix and other can say language name as suffix, kaknd or kndka or knka)
Glyph name - Ligature
If a glyph shape is formed by two or more unicode values and the resultant glyph doesn’t have any unicode value then the glyph should be named as combination of two glyph names seperated by underscore. Suffix can be added to differenciate between multiple ligatures for the same unicode value combination. In the below example, suffix .abvs is used since this ligature will be used in opentype feature abvs (above base substitution).
An example to understand how this reverse lookup works. Kannada text ಮಂಕುತಿಮ್ಮ, Unicode splitup and glyph names for the same is
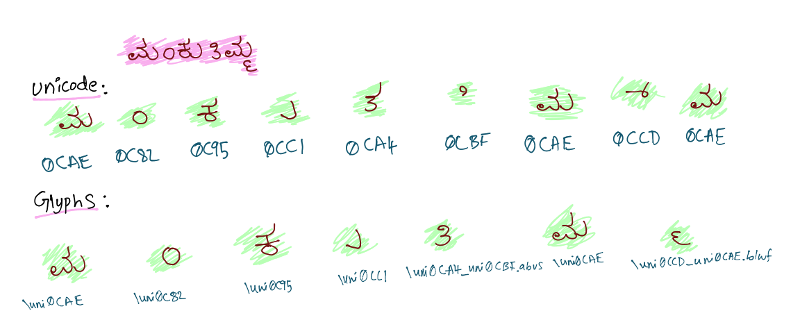
Glyph names stored inside pdf are as follows(ignores all the suffix and joins together using underscore)
0CAE_0C82_0C95_0CC1_0CA4_0CBF_0CAE_0CCD_0CAEFollowing psudo code shows how to convert unicode string to glyphs list without any help of rendering engine.
def get_glyphs_list(unicode_str):
glyph_seq = []
for letter in unicode_str:
n = (hex(ord(letter)).replace("0x", "").upper().zfill(4))
glyph_seq.append(n)
return "_".join(glyph_seq)
# Example:
print get_glyphs_list(u"ಮಂಕುತಿಮ್ಮ")
# Output:
# 0CAE_0C82_0C95_0CC1_0CA4_0CBF_0CAE_0CCD_0CAEWhen we fetch glyph list for text ಕಿ above function returns 0C95_0CBF, which is easy to search from the available glyph list.
Problems:
In case of vattakshara, for example ತಿಮ್ಮಿ, dependent vowel will be reordered as shown in the image below, so resultant glyphset will be 0CA4_0CBF_0CAE_0CBF_0CCD_0CAE but above function returns as 0CA4_0CBF_0CAE_0CCD_0CAE_0CBF.
Glyph names validator:
I created a tool using python to validate the glyph names, which accepts two parameters a font file and a text file with possible letters/words. It uses hb-shape to get the glyphs list from the input text file, and generates required glyphs list and compares between them.
Download the python script from here
python validate_glyphnames.py Gubbi.ttf kannada_tests.txtSample test file
ಅ
ಆ
ಇ
ಈ
ಕಾWill write more about this tool later, If glyph names are standardized then we can create lot of automation tools.
Let us start using the glyph names as uniXXXX format, I am not sure about the solution for above mentioned problem, let me know your suggestion.
C & S welcome.
About Aravinda Vishwanathapura
Co-Founder & CTO at Kadalu Technologies, Creator of Sanka, Creator of Chitra, GlusterFS core team member, Maintainer of Kadalu Storage